6. Parallelisation#
CROCO has been designed to be optimized on both shared and distributed memory parallel computer architectures. Parallelization is done by two dimensional sub-domains partitioning. Multiple sub-domains can be assigned to each processor in order to optimize the use of processor cache memory. This allow super-linear scaling when performance growth even faster than the number of CPUs.
Related CPP options:
OPENMP |
Activate OpenMP parallelization protocol |
MPI |
Activate MPI parallelization protocol |
OPENACC |
Activate GPU computation protocol |
MPI_NOLAND |
No computation on land only CPUs (needs preprocessing) |
AUTO_TILING |
Compute the best decomposition for OpenMP |
PARALLEL_FILES |
Output one file per CPU |
NC4_PAR |
Use NetCDF4 capabilities |
XIOS |
Dedicated CPU for output (needs XIOS installed) |
Preselected options:
# undef MPI
# undef OPENMP
# undef MPI_NOLAND
# undef AUTOTILING
# undef PARALLEL_FILES
# undef NC4_PAR
# undef XIOS
6.1. Parallel strategy overview#
Two kinds of parallelism are currently supported by CROCO: MPI (distributed memory) or OpenMP (shared memory).
CROCO doesn’t currently support MPI+OpenMP hybrid parallelisation: use of cpp keys MPI or OPENMP is exclusive.
6.1.1. OpenMP (#define OPENMP)#
Variables in param.h:
NPP: a number of threadsNSUB_X: number of tiles in XI directionNSUB_E: number of threads in ETA direction
NSUB_X x NSUB_E has to be a multiple of NPP. Most of the time, we set NPP=NSUB_X*NSUB_E
Example 1:
One node with 8 cores: NPP=8, NSUB_X=2, NSUB_E=4

Each thread computes one sub-domain.
Example 2:
Still one node with 8 cores: NPP=8, NSUB_X=2, NSUB_E=8

Each thread computes two sub-domains.
Code structure
OpenMP is NOT implemented at loop level
but uses a domain decomposition (similar to MPI) with parallel region
use of First touch initialisation so working arrays are attached to the same thread
working arrays have the size of the sub-domain only

Example of a parallel region#

Inside a parallel region#
Here Compute_1 and Compute2 can’t write on the same index of a global array.
6.1.2. MPI (#define MPI)#
Variables in param.h:
NP_XI: decompostion in XI directionNP_ETA: decomposition in ETA directionNNODES: number of cores (=``NP_XI*NP_ETA``, except withMPI_NOLAND)NPP = 1NSUB_XandNSUB_ETA, number of sub-tiles (almost always =1)

Example 1:
8 cores:
NP_XI=2, NP_ETA=4, NNODES=8
NPP=1, NSUB_X=1, NSUB_E=1

Example 2:
8 cores:
NP_XI=2,NP_ETA=4,NNODES=8NPP=1,NSUB_X=1,NSUB_ETA=2

6.2. Variable placement for staggered grids#
We are working on a staggered grid.
For the barotropic solver, there are 3 different grid points where the variables are stored:
RHO: This variable is “centered” at each grid cell.U: This variable is at the left/right edge of the grid cell.V: This variable is at the top/bottom edge of the grid cell
6.3. Loops and indexes for staggered grids#
6.3.1. Parallel/sequential correspondence:#
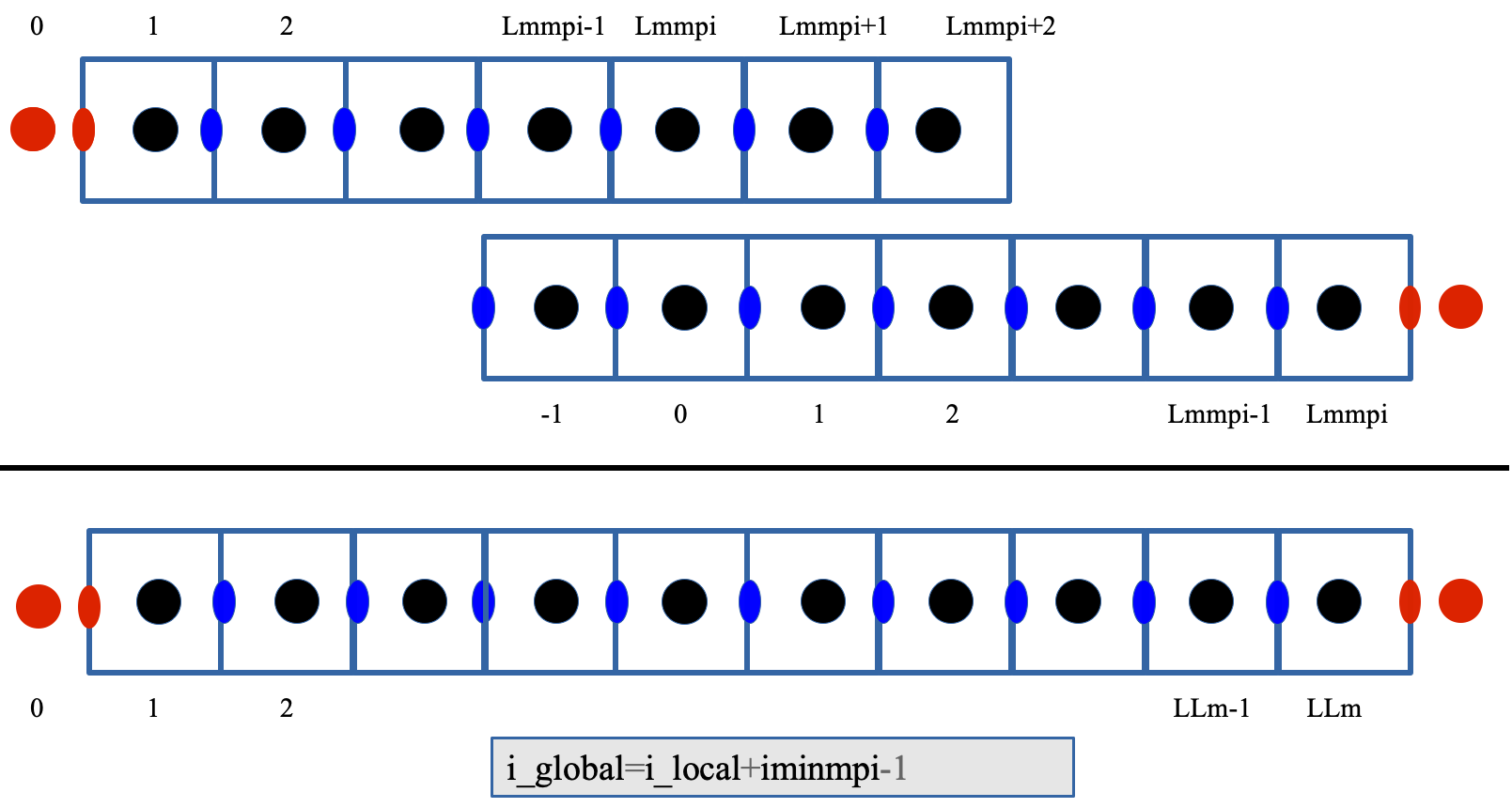
The top image depicts a decomposition of the domain into 2 sub-domains.
The bottom image shows the indices for the total (sequential) domain.
6.3.2. Decomposition:#
Example : 2 MPI domains, with 2 sub-domains for each MPI rank (with or without OpenMP)
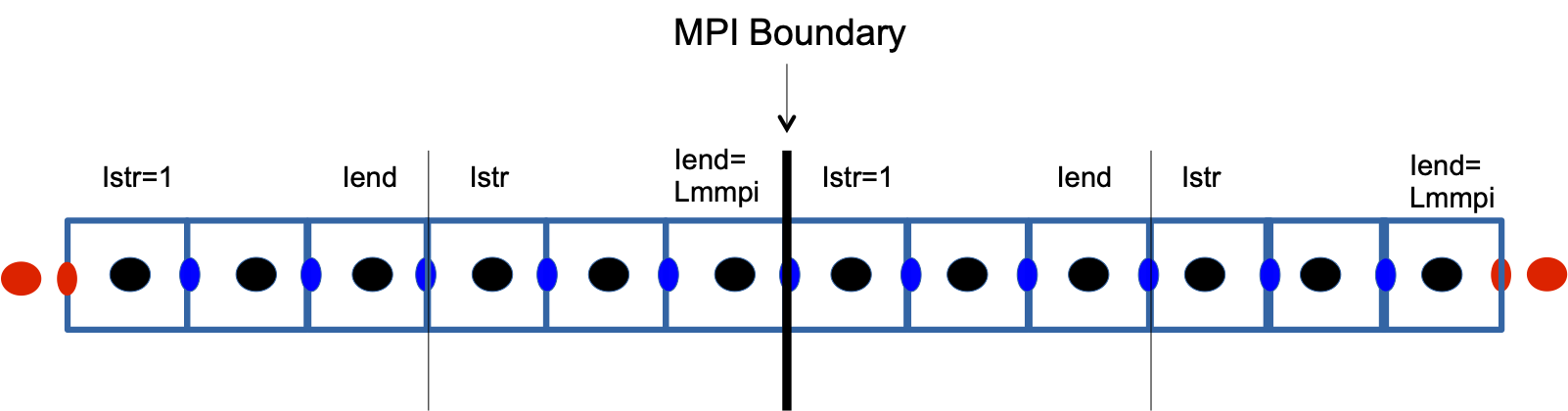
Istr, Iend are the limits of the sub-domains (without overlap).
They are calculated at the beginning of the subroutine by including

Computation of Istr, Iend and use of working arrays.
6.4. Halo layer exchanges#
CROCO makes use 2 or 3 ghost cells depending on the chosen numerical schemes.
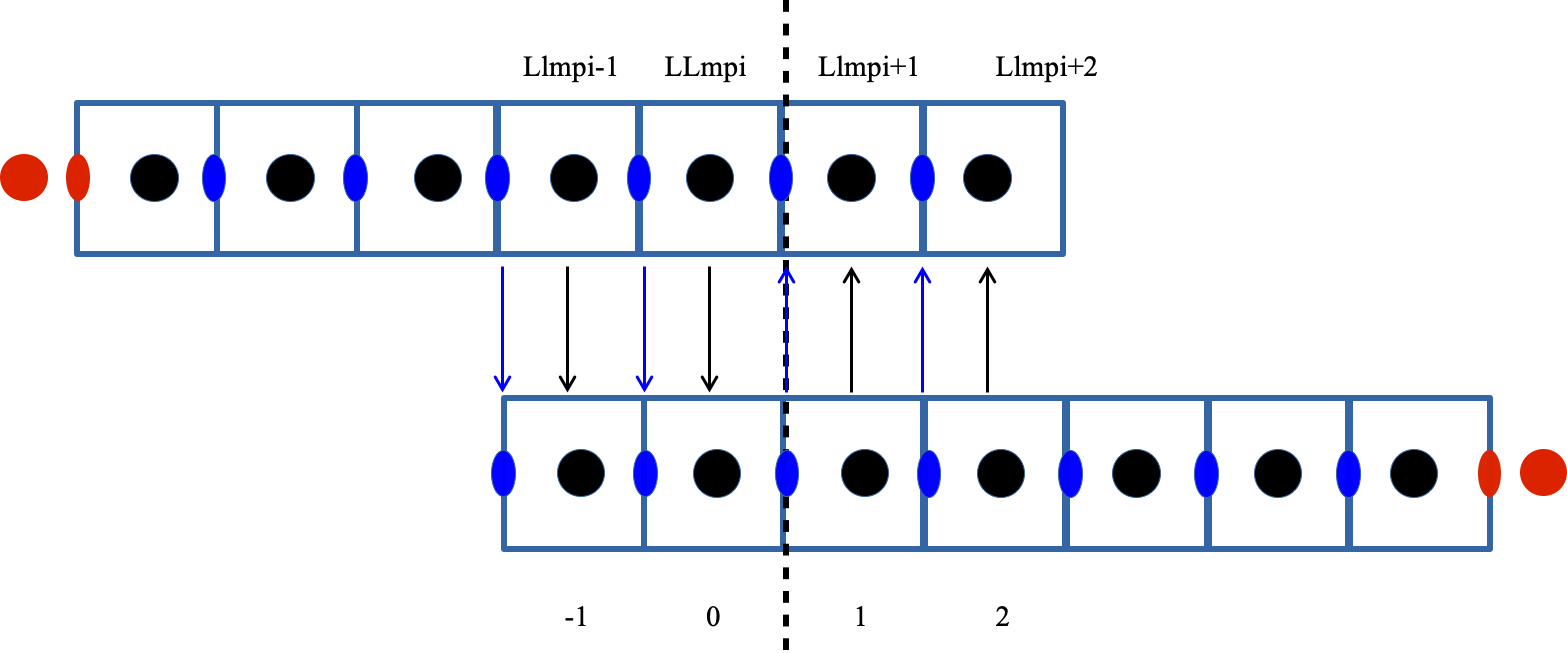
In the example above (2 ghosts cells), for correct exchanges, after computation:
\(\eta\) has to be valid on
(1:Iend)\(u\) has to be valid on
(1:Iend)except on the left domain(2:Iend)

IstrU is the lower limit of validity of the U points.
Computation of auxiliary indexes is done by including a file:
subroutine step2D_FB_tile (Istr, Iend, Jstr, Jend, zeta_new, ...
...
#include "compute_auxiliary_bounds.h" ! Compute IstrU, IstrR
6.5. Dealing with outputs#
By default, with MPI activated input and output files are treated in a pseudo-sequential way, and one NetCDFfile corresponds to the whole domain. This has drawbacks when using a large number of computational cores, since each core is writing its part of the domain sequentially, the time dedicated to outputs increase with the number of cores. Three alternatives are implemented within CROCO.
Splited files (#define PARALLEL_FILES)
In this case, each core is writing its part only of the domain in separated files (one per MPI domain). This writing is performed concurrently. One other advantage is to avoid the creation of huge output files. The domain related output files can be recombined using ncjoin utility (in fortran) compiled in the same time than CROCO. Note that in this case, input files have to be splited as well, using partit utility.
Parallel NetCDF(#define NC4PAR)
This option requires NetcDF4 verion, installed with parallel capabilities. All cores are writing concurrently but in the same time.
IO server (#define XIOS)
XIOS is an external IO server interfaced with CROCO. Informations about use and installation can be found there https://forge.ipsl.jussieu.fr/ioserver. In this case, output variables are defined in .xml files. See also the Diagnostics chapter.
6.6. Run with GPU#
OpenACC directive-based approach is the most appropriate method to develop the GPU version of croco. Low development cost, a single program repository can be shared by CPU and GPU. Similar to OpenMP style which is familiar to many users. An openacc compiler compatible is necessary : only nvfortran, and old pgi have been tested.
To run croco on GPUs, the key OPENACC as to be set in the cppdefs.h file. With MPI, all the mpi process are dispatch over the GPUs. Effiency is better with one or two mpi by GPU card.
#define OPENACC
6.6.1. General implementation#
Implementation is done by inserting basic OpenACC directives :
Kernels or parallel directives : Basically, inserted into the outermost of nested loops
Loop independent/seq directives : Inserted according to the loop algorithms
No quantitative configurations for GPU threads are specified. Gang or vector clauses are not applied, leaving it to the compiler’s decision.
Exemple from pre_step3.F
!$acc kernels if(compute_on_device) default(present)
!$acc end kernels
!$acc parallel loop if(compute_on_device) default(present)
6.6.2. Data directives#
Remove redundant data transfer between CPU and GPU. There is one main copy data to device, on copy-back before output. The file copy_to_devices.h do this job.
Python script common2device.py generate the file copy_to_devices.h
and have to be rerun when *.h files are modified.
6.6.3. 3D loop tunning with preprocessing by compilation#
For GPU efficiency some 3D loops have to be reordered or variable expand. This is done by en additional preprocesing (in python). And it’s added in jobcomp compilation procedure. Two kind of transformations, first one transforms 2D variables internal to loops in 3D variables. Second restructures loop with z dependencies.
Example 1:
# if defined OPENACC
DOEXTEND(k,1,N,FX,FE,WORK)
# endif
... FX(i,j) will become FX_3D(i,j,k) (FE_3D, WORK_3D )
# if defined OPENACC
ENDDOEXTEND
# endif
Example 2:
DOLOOP2D(Istr,Iend,Jstr,Jend)
do k=1,N
do i=Istr,Iend
DC(i,k)=1./Hz_half(i,j,k)
enddo
enddo
...
ENDDOLOOP2D
Become in CPU version:
!$acc kernels if(compute_on_device) default(present)
!$acc loop private( DC, FC, CF)
do j=Jstr,Jend
do k=1,N
do i=Istr,Iend
DC(i,k)=1.D0/Hz_half(i,j,k)
enddo
enddo
do i=Istr,Iend
DC(i,0)=cdt*pn(i,j)*pm(i,j)
enddo
...
enddo
And become in GPU version :
!$acc kernels if(compute_on_device) default(present)
DO j=Jstr,Jend
!$acc loop private(DC1D,CF1D,FC1D) vector
DO i=Istr,Iend
do k=1,N
DC1D(k)=1.D0/Hz_half(i,j,k)
enddo
DC1D(0)=cdt*pn(i,j)*pm(i,j)
ENDDO
...
ENDDO